
About Me
About Me
About Me
I’m working as an AI Researcher at Together AI, on pre-training and finetuning Large Language Models, cooking up data recipes, and building out training framework features as needed. Lately I’ve been digging into long-context training and model distillation.
Before this, I got my MSc in Computer Science from NYU’s Courant Institute of Mathematical Sciences, where I explored Reinforcement Learning from Human Feedback for LLMs at OLAB, NYU Langone. I’ve also done research at CVIT Lab at IIIT-Hyderabad along with industry data science roles, working on information extraction, machine translation, and question-answering.
These days I’m most excited about RL for language models, systems work around attention, and multimodality. Also I keep an eye out for ML infrastructure.
Check out my CV for more detailed info.
Featured Projects
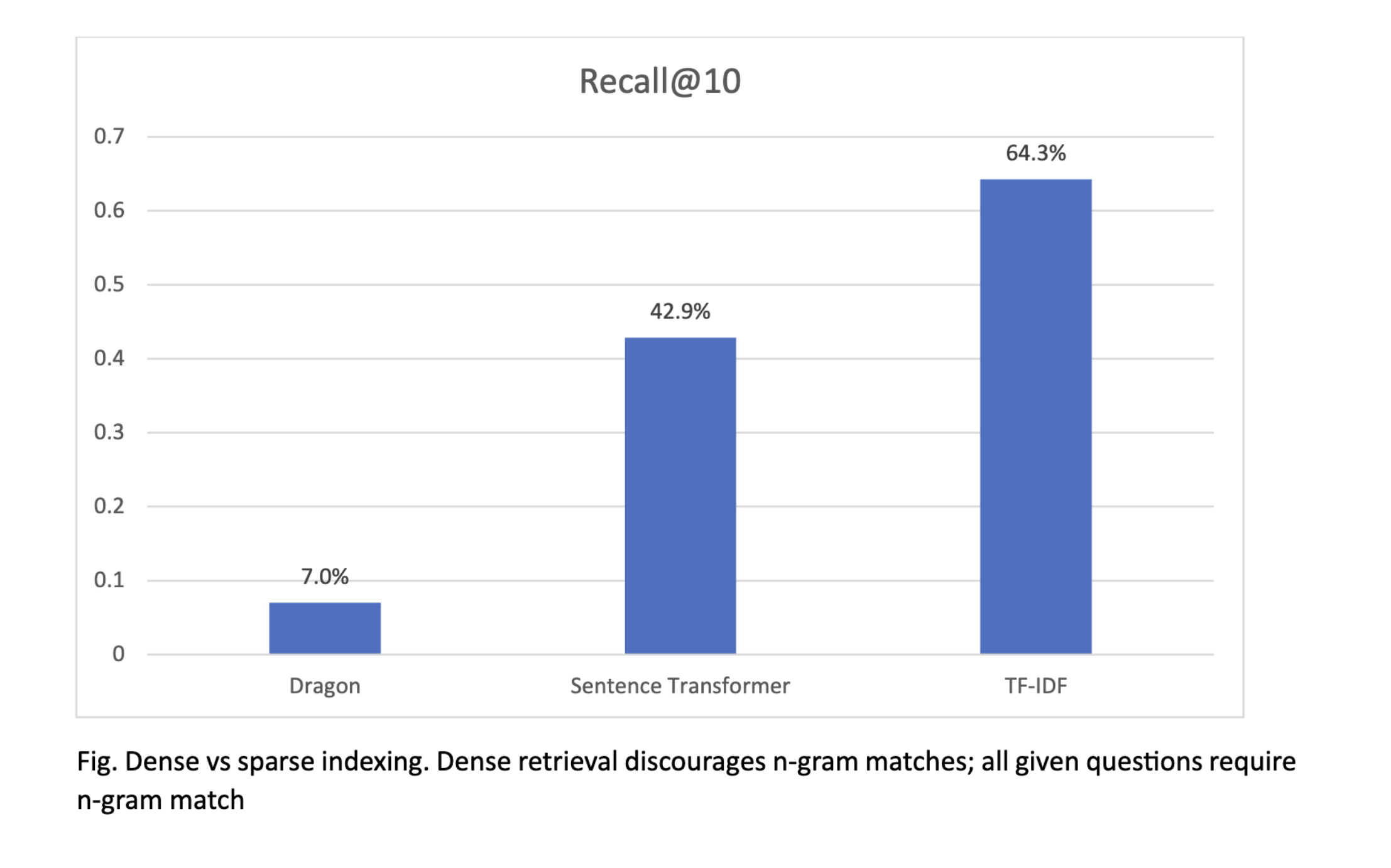
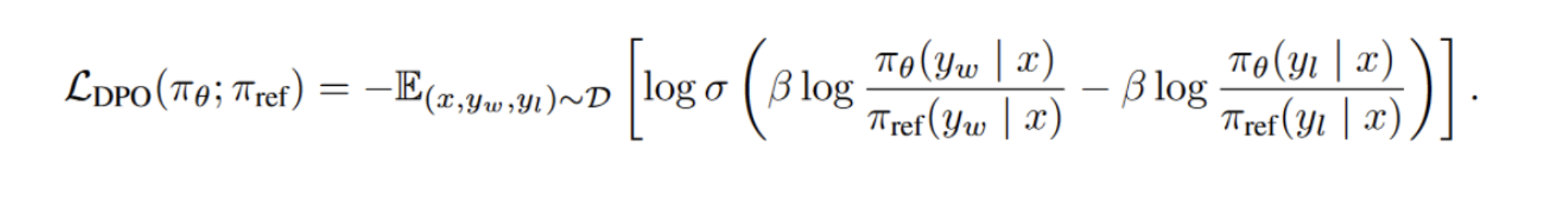
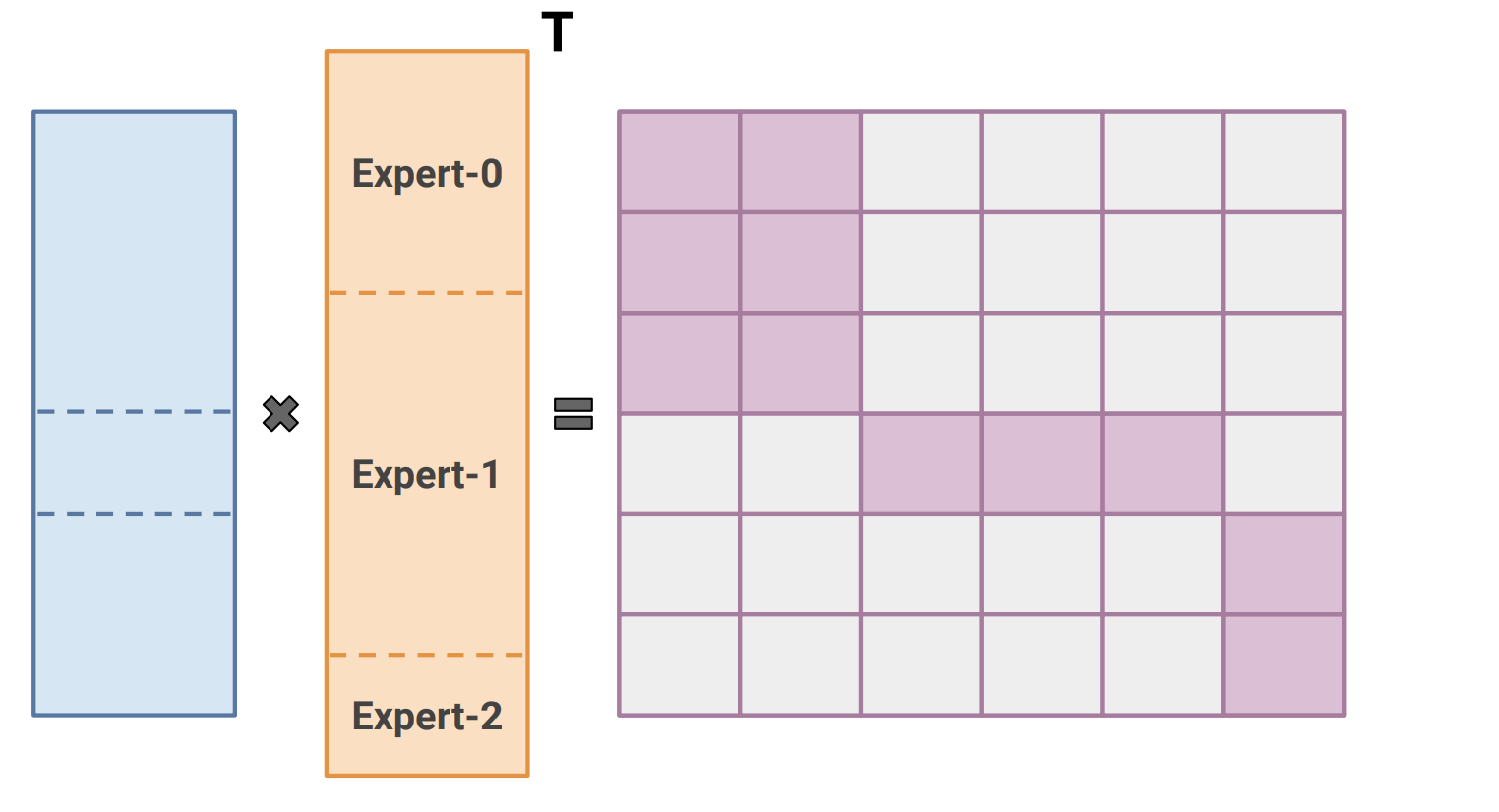
Paper Digest
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning February 01, 2024
Visual Instruction Tuning (LLaVA) January 20, 2024
DINOv2: Learning Robust Visual Features without Supervision March 01, 2024
Selected Talks
GPT-3: Language Models are Few-shot Learners - Large Language and Vision Models Symposium, NYU Center for Data Science, 2024
Llama 2: Open Foundation and Fine-Tuned Chat Models - Large Language and Vision Models Symposium, NYU Center for Data Science, 2024
Generative Agents: Interactive Simulacra of Human Behavior - Large Language and Vision Models Symposium, NYU Center for Data Science, 2024
Conferences
MLSys 2025 - Conference on Machine Learning and Systems
NeurIPS 2025 - Conference on Neural Information Processing Systems